 News in English
News in English
It is well known that a clincal trial must include a sufficient number of patients in order for the study to get a high power. For a pivotal study aiming at marketing application, 90% power is normally required, and to achieve that, hundreds or sometimes thousands of patients may be needed.
What does that mean? And why? Why 17’000 patients for a drug against heart disease, and only 300 for an immunotherapy against cancer? I sometimes get asked: How do you calculate the power? What is it that you calculate?
Ninety percent power of a study means the study has 90% probability of getting positive, i.e. of giving a statistically significant treatment effect according to the primary endpoint of the study. And, this probability is given under the assumption that the treatment effect truly exists, and that it is as large as we believe or hope it is.
There are mathematical formulae for calculation of the sample size needed for a given power in some simple cases, but I find it more informative to explain the concept through simulations. Simulations is the fall-back approach which must be used ever so often when no formula fits the particular study at hand.
Say for example that a treatment is estimated to lower the patients’ systolic blood pressures (SBPs) by 17 mmHg more than placebo on average, with a standard deviation of 35 mmHg, based on earlier studies. It is probably reasonable to assume the change in SBP to be normally distributed between patients. Given these prerequisites, we can simulate a fictive clinical trial with, say, 25 patients per treatment arm in a parallel groups design. We simulate exactly the study design we planned for the true, coming study, with exactly the same primary endpoint: change from baseline in SBP, based on the normal distribution and with a mean difference of 17 mmHg between treatment groups. We then perform exactly the planned statistical analysis of the study: a t-test, and note whether the study falls out as positive or negative. We have now simulated one fictive study, an in silico-study.
I prefer to take things slowly, but in fact we simulate 1’000 in-silico studies using the same prerequisites. Some of the studies will be positive – with a statistically significant difference in SPB change from baseline between the active treatment group and placebo – and some of the studies will be negative. If 654 of the fictive studies turn out positive, we conclude that 25 evaluable patients per group are needed for our real study to get 65.4% power. By repeating the simulation exercise with different sample sizes we can deduce the number of patients needed for the study to get 90% power, for example using a figure like this one:
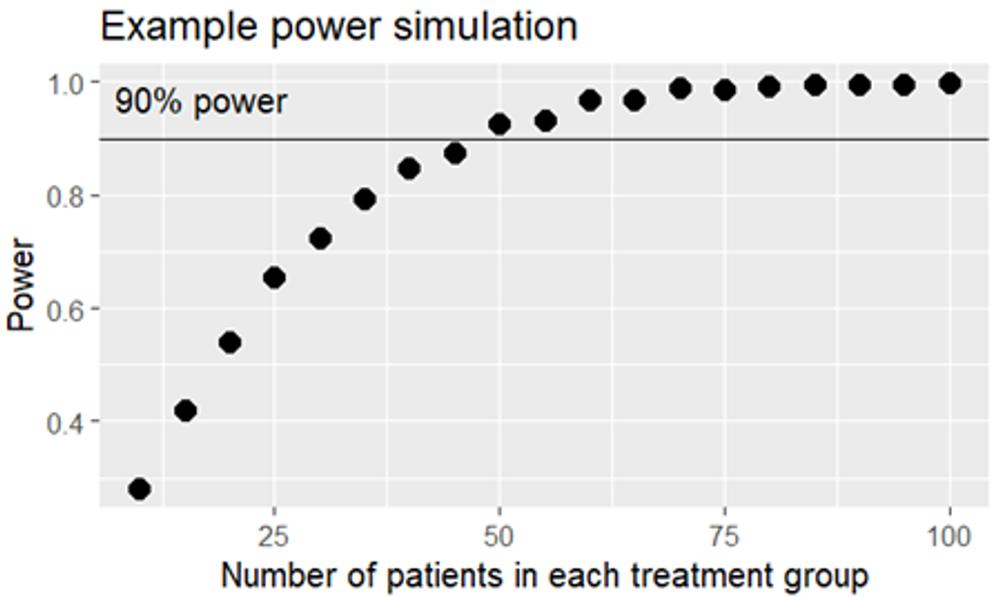
We deduce that 50 + 50 patients will give enough power. If the data were less well behaved we would need a non-parametric test instead of a t-test, and fewer in silico-studies would be positive, so more patients would be needed to achieve 90% power. And had the difference between the groups been smaller, we would also have needed more patients. A study to prove something as small as a 3% reduction in heart disease incidence would need many thousand patients.
You surely do realize that even the smallest changes in study assumptions may influence the estimated sample size needed. And how is it even possible to guess the magnitude of the treatment effect before performing the study?
Efforts are made to estimate the magnitude of the treatment effect in advance, based on earlier studies, your own or others’ published research, clinically reasoning, and sometimes on calculations and simulations. A different strategy is to determine the minimum effect of interest to be proven with the study. Such a target gives an upper limit for the number of patients worth studying. If the study fails, the conclusion is that the effect was too small to be of clinical interest.
In practice we make a whole lot of calculations, with varying study designs and assumptions regarding for example the treatment effect. We need a complete overview of our chances of study success under all possible circumstances. Or as complete as possible. In order to understand the number of patients needed. In order to give the sponsor a reasonable chance of study success – not too low, not unnecessarily high. In order for the study to become ethically acceptable.
This column has also been published in the newsletter "Statistik är mer än siffror".
 BREAKING
BREAKING